Cubes are made up of a fact table and several dimensions. Optimizing cube processing therefore, involves optimizing dimensions also. Let us look at two scenarios. One in which the dimensions are not optimized and the cube is processed and another in which the dimensions are optimized and the cube is processed.
When the dimensions of a cube are not optimized the time taken for processing the cube is longer than the time taken for processing the cube after the dimensions are optimized. In the Process log window the time taken for processing is indicated in line three. The Processing of cube budget took roughly 2 seconds. The processing of the partition Budget took1 second. Total number of rows processed in 2400.

How do we optimize dimensions? For each row in the fact table, the Analysis server must be able to identify a single, specific leaf level member in the Dimension table. If the Member Key Unique property of a leaf level member is set to false, Analysis server will retrieve the key column for the next level up in the hierarchy. This process will continue up to the top level of the hierarchy, until it encounters a member whose Member key Unique is set to True. This takes up a lot of processing time. Once this is optimized all redundant levels are removed and the overall performance improves.
Optimizing the Cube
Any SQL statement executed on a cube, draws its values from the Member key Column property of the Dimension table though the data is available in the fact table. This takes up processing time and can be avoided. The Member Key Column property definition can be changed within a specific cube so that the data can be retrieved directly from the fact table.
1. Right click on the sales cube and click Edit
2. Expand the Customer dimension and select Customer name level and look at the properties pane.
|
|
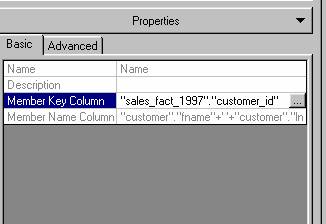
3. Note that all properties are disabled, except the Member Key Column property. The cube editor allows the user edit the Member Column Key property so that it can be changed from being the primary key of the dimension table to the foreign key of the fact table. This need not be done for every dimension manually. A single command will convert the Member key Column values from the dimension table to the fact table wherever possible.
4. Click on Optimize schema in the Tools Menu 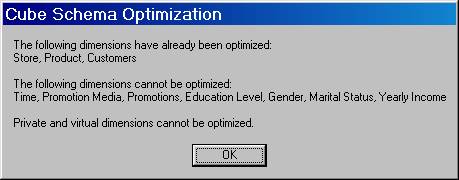
5. Since we had already optimized the dimensions of this cube in the previous lesson we get the message that the cube is already optimized. Otherwise you would get the message that various levels Member Key Columns are being optimized as in the case of the Warehouse cube below.
|
|
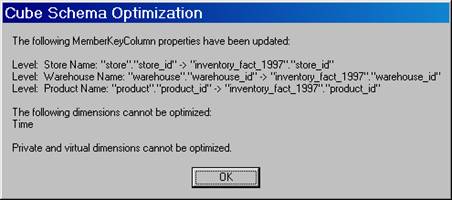
6. Now click save and save the Warehouse cube and Process the cube and check on the time taken to process the cube. It will be 1/5th the time normally taken for processing an un-optimized cube.
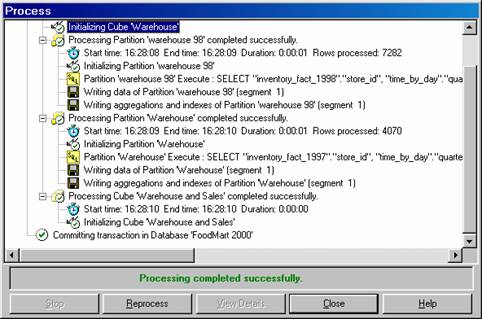
7. The processing of the various partitions took only 1 second to process. Though this is not an earth shaking improvement it will be significant for cubes which have large dimensions.
The loading of a cube can be optimized fully when the dimensions are shared. Optimizations require that the Member Key Column is moved from the lowest level of the dimension to the fact table. In shared dimensions the dimension has an independent existence from the cube and the Member Key Column can be differently specified in the dimension and the cube. With a Private dimension the Cube Editor can be used to define the Member Key Column of the Dimension and there is no possibility of creating dual definitions of the Member Key Column for a level in the dimension.
Full optimization of a shared dimension leaf level member can be done using the Dimension Editor. Within the Dimension Editor the leaf level members Member Key Column should be set to true and then the Optimize schema command should be invoked in the Cube Editor to move the Member Key Column from the dimension to the fact table.