 Overview of Oracle Partitioning By the time of Oracle 11g versions and talks on further releases, the concept of partitioning is not a new icing in the database technology. It has been the part of Oracle database since its 8.0 release (1997) and has been a proven functionality which ensures performance, manageability, and systematic data availability.
Overview of Oracle Partitioning By the time of Oracle 11g versions and talks on further releases, the concept of partitioning is not a new icing in the database technology. It has been the part of Oracle database since its 8.0 release (1997) and has been a proven functionality which ensures performance, manageability, and systematic data availability.
Topics
Partitioning is the method which physically segregates large tables or indexes can be realized into smaller logical groups. Each logical piece is a realizable table or index, and referred as a ‘partition’. The one principle which forms the basis of partition is ‘Divide and win’; the more you divide the data management, more easier would be the administration.
The tutorial shall cover the theoretical and conceptual overview of Partitioning feature in Oracle. We shall see the understanding of the partitioning concept, its benefits, usage guidelines and strategic considerations.
Partitioning: The Concept
Partitioning is feature which is often implemented by DBAs during the design phase. These implementation considerations are the part of the phase between the logical design and physical design. The data forecasting is an important aspect of the process, which forms the basis of partitioning. The tables where the data grows regularly at high rate are the best candidates of partitioning.
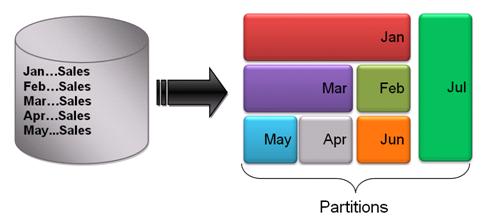
For instance, the SALES data of a growing product company grows exponentially. The monthly SALES report queries stuck more time it is executed. Tuning strategy like index range scan (on month column) doesn’t improve the scenario still. The DBA identifies the flaw in the table design. The table data was expected to grow at high rate and performance was an obvious challenge in the future. The SALES table should have been designed as below.
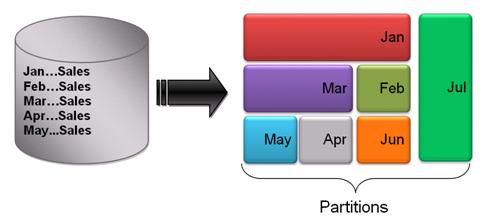
The Non Partitioned SALES table has been partitioned based on the Month
The above figure shows the transformation of a non partitioned SALES table to a Partitioned table.
As stated earlier, each logical piece of a table is referred as a partition. A partition has its own name, storage mechanism, and statistics. Multiple partitions of a single table can be administered in a different way, which gives flexible manageability to a DBA.
Partitioning: The benefits
The key objective served by the partitioning is query performance. It has been quite obvious and usual that small chunk of data is easier to locate, manage, and well segmented. Whenever a SQL query on a Partitioned table is executed, Oracle optimizer first locates the partition specified in the query or where the required data exists. Therefore, instead of scanning the complete table, only the specific partition is queried. This improves the query process and run time performance. The flow is named as Partition Pruning as it evades out major volume of data from the table before the query search begins.
Besides performance, the partitions provide easy maintenance and monitoring benefits. Each partition can carry different storage specifications or can be administered with different mechanisms as required. This feature can be of great help during individual partition operations like exchange, movement or Oracle export.
The admin strategies can differ from partition to partition. For example, each partition of the table can be adjusted in a different tablespace. This distributes the data across the disk. It not only widens the focus but also expands the scope of trying out multiple strategies in data loading, data replication, and data management. In addition, rebuild index by partition, partition compression, partition movement across tablespaces, partition exchange or updates are the usual benefits of partition administration.
Partition a Table: Guidelines
Partitioning is an iterative process. Ideally, the decision on partitioning strategy must come just after the logical modeling. Guidelines to partition a table:
- Large tables where size exceeds 2 GB
- Tables which contain periodic data like sales, accounts, ranges, or location
- Tables where data migration is expected from different systems
Partition an Index: Guidelines
An index on a non partitioned table can be partitioned. Multiple segments of a partitioned index are bifurcated as multiple branches, thus reducing the access concentration on single index area. This reduces the cache buffer chain waits. In addition, the index can rebuild by partition.
Guidelines to partition an index:
- When index is on a number column and column value grows incrementally; thus creation huge contention amongst the values
- Rebuilding the index for some part of data only
- Maintenance of the index on some part of data only
- Perform maintenance on parts of the data without invalidating the entire index.
Partitioning: The Strategy
With every release of Oracle, the partitioning strategy has been strengthened, which has taken the flight from instrumental to advisory level. Oracle 11g offers matured and comprehensive set of strategies to model the data in way, which is best suited for the application and hence, the business. We shall look upon the basic partitioning strategies and thereafter move on to the advanced strategies.
Partitioning Key
Partitioning key is the set of column(s) which form the baseline of Partitioning strategy within a table. For example, the SALES data has to be partitioned for each month. So, ‘Month’ column is a partitioned key here. The partitioning key constitutes the columns of the same table and form logical groups, known as Partition. The values of these columns decide the appropriate partition for an incoming row data, where it has to reside. Oracle automatically directs insert, update, and delete operations to the appropriate partition with the partitioning key.
Partitioned Indexes
Until Oracle 11g, three types of indexes were realizable in partitioning scenarios. The indexes can be Local indexes, Global Partitioned Indexes, or Global Non-partitioned Indexes. Let us see their working and impacts.
1. Local Index – An index specifically created and effective for a single partition is a local index. They are extensively used in Data warehousing environments.
2. Global Partitioned Index – An index created on a table (partitioned or no partitioned) that can be partitioned on a key, which is similar or different from the table. It implies that a table and an index on the same table can have different number of partitions. They are best suited for OLTP models.
3. Global Non – partitioned Index – The conventional B-Tree or unique indexes on non partitioned tables. It needs the reference here to differentiate them from partitioned indexes.
Partitioning Criterion
Under the basic methods of partitioning, we shall see the primitive strategies followed to partition a table.
By Range – Under this method, a table is partitioned based on the ranges of a column (partitioning key). The range can be periodic or numeric. It was released as a partitioning enhancement in Oracle 8i release. For example, a partition of year range ‘2011’ will have data from 1st Jan, 2011 to 31st Dec, 2011. Similarly, a partition by age range ’25-50’ will have data of all employees whose age falls between 25 and 50.
By List – The list partitioning refers to a method where the table is partitioned based on unordered and fixed values of a column (partitioning key). For example, country wise population stats data can be divided based on ‘Country Code’. Likewise, details of Oracle professionals can be partitioned based on their corresponding ‘Oracle User Group’.
By Hash – The hash method is approached only when the objective is to evenly distribute the data in hashes. When the partitioning key has unstructured value sets, hash partitioning is the best solution.
It is recommended that the partitioning key must use exact fixed values to make use of partition pruning. If a hash uses range of values of partitioning keys, it might be tough to identify the exact partition. With ranges, some important utilities like split, drop and merge functionalities would be disabled.
Now, using on the above partitioning strategies, a table can be partitioned as a single level or multi level (Composite) partitioned table
A table follows Single level Partitioning if it uses one of the partitioning methods. composite Partitioning applies to a table if it uses more than one partitioning methods to define a partition or sub-partition. A partition within a partition is known as Sub-partition. The table is first partitioned using one of the methods. Thereafter, each partition is broken into sub-partition using another partitioning method.
For example, SALES table is partitioned using Product Id as partitioning key, using List partitioning method. Thereafter, each “Product” partition is further partitioned into “Monthly sales” sub-partitions using Range partitioning method.
The figure below demonstrates the Composite partitioning.
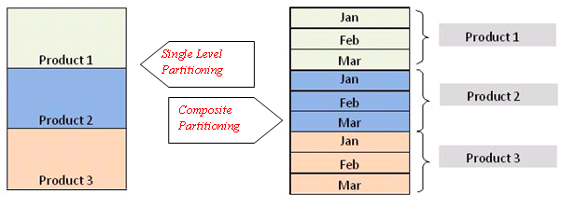
The composite partitioning can be implemented as Range-Hash (Oracle 8i) and Range-List (Oracle 9i). Oracle 11g saw considerable enhancements towards composite partitioning and made other combinations available too. These combinations were Range-range, List-range, List-hash, List-list, Interval-list, Interval-hash, and Interval-range.
We shall cover Interval partitioning under advanced partitioning techniques.
Advanced Partitioning Techniques in Oracle 11g
Partition strategies have been enhanced and strengthened with each release of Oracle. These enhancements have been instrumental in improving manageability of partitioned tables. Oracle 11g made considerable improvements in partitioning techniques and partition key actions. We shall discuss them as below.
Interval Partitioning – It’s a fresh addition in partition methods in Oracle 11g. It’s a derivative of range partitioning method where all partitions are of equal interval (similar to a range). The difference between “Range” and “Interval” lies during the partition creation. In “Range”, all partitions have to explicitly specified and created by the user. But in “Interval” method, partitions are implicitly created by Oracle based on the “Partitioning principle”. This principle is a part of the table partitioning clause. This brings in the generic behavior of the partitioning.
For example, SALES data can be “interval” partitioned based on the Year. If the table is partitioned using range partitioning, all partitions have to be explicitly created with a defined “Partition Name”. It can become a tedious maintenance job in future as a new partition has to be appended every year to archive the data of the last year. On the other hand, for an “Interval” partitioned table, Oracle automatically creates partition for each year, as the fresh data comes.
Additionally, the partitioning key must be of NUMBER or DATE type. Also, it is not supported for Index organized tables.
REF Partitioning – Oracle 11g introduced this peculiar partitioning feature to support referential integrity within the partitions. If the parent table is partitioned using any of the partitioning techniques on the basis of a partitioning key, the child table automatically inherits the partitioning scheme from its parent. Though partitioning key is not present in the child table, the child record will reside in the same partition where the corresponding parent record resides. One can query the child table with the same partition name as that in the parent table. It reduces the overhead of including key columns in the child table and creating partitions.
For REF partitioning, the partitioning key values in the parent table must not be null. The parent table cannot be partition using Interval partitioning.
The REF partitioning technique also inherits the partition storage and operational activities, which are responsible for the transformation from parent to child. In addition, it also enables the partition wise joins for the similar partitions in parent and child table. It works as a performance booster too.
Virtual Column Partitioning – By virtue of Virtual column partitioning, a partitioned table can have a virtual column as partitioning key. This implies that partitioning key can be based on a column which physically doesn’t exist in the table, but exists as an expression which uses physical columns of the same table. Creation of virtual columns in tables was introduced in Oracle 11g.
For example, management decides to calculate a product order’s cost using a virtual column (Order Cost = Order Quantity * Product Cost) in the SALES table. Now based on the Order cost, the data should be directed to appropriate partition. Here comes the virtual column based partitioning. The table can be range/interval partitioned on the ‘Order Cost’ as partitioning key.
In all the partitioning methods discussed above, partition key can be a virtual column.
System Partitioning – It is an administrative partitioning method, introduced in Oracle 11g, where each partition resides in a different tablespace. The most interesting part of this method is that it doesn’t rely on the partitioning key. Subsequently, there is partitioning pruning and no local index applicable for system partitioning.
It ensures proper distribution and allocation of data on the disk. All the insert statements must explicitly specify the partition name along with the table name.
Partitioning Metadata
Oracle maintains the partition related information in the data dictionary views which maintain their information in sync with the current partitioning actions. The views are listed as below
- [ALL | DBA | USER]_IND_PARTITIONS
- [ALL | DBA | USER]_IND_SUBPARTITIONS
- [ALL | DBA | USER]_LOB_PARTITIONS
- [ALL | DBA | USER]_LOB_SUBPARTITIONS
- [ALL | DBA | USER]_PART_COL_STATISTICS
- [ALL | DBA | USER]_PART_HISTOGRAMS
- [ALL | DBA | USER]_PART_INDEXES
- [ALL | DBA | USER]_PART_KEY_COLUMNS
- [ALL | DBA | USER]_PART_LOBS
- [ALL | DBA | USER]_PART_TABLES
- [ALL | DBA | USER]_SUBPARTITION_TEMPLATES
- [ALL | DBA | USER]_SUBPART_COL_STATISTICS
- [ALL | DBA | USER]_SUBPART_HISTOGRAMS
- [ALL | DBA | USER]_SUBPART_KEY_COLUMNS
- [ALL | DBA | USER]_TAB_PARTITIONS
- [ALL | DBA | USER]_TAB_SUBPARTITIONS
Conclusion
Partition is a proven database feature in variety of database applications. Easy implementation, simplified administration, less complex, and robustness are some of the biggest differences which make it an obvious choice during modeling phase of an application.
Surely, Oracle would continue to pay special attention towards partitioning techniques in future and expect some new enhancements and additions in upcoming releases.
[catlist id=185].