ROLAP stores aggregations in a relational database and hence it does not make sense to select ROLAP as a storage mode for cubes if the aim is to have speed of performance in analysis. Aggregations in Relational databases are slow and bulky and it defeats the very purpose of creating the aggregations. However, if the user wants to look at the aggregations and understand how they work, then ROLAP is the best storage mode.
MOLAP and HOLAP aggregations are similar. The only difference lies in where the detail level values are stored. MOLAP consumes more space than HOLAP, because the former duplicates the data in the fact table. Queries that use the data will however be efficient. HOLAP on the other hand does not duplicate the data but the queries on the detail data will tend to be slower in comparison. However, processing of a HOLAP cube is faster than the processing of a MOLAP cube.
Storage Design Wizard
In the Analysis Manager tree pane, under the database that contains the cube for which the storage options is to be set and design aggregations, expand the Cubes folder.
Right-click the cube for which storage options is to be set and design aggregations, and then click Design Storage.
If the cube storage design has already been selected the user will be show the screen as under:
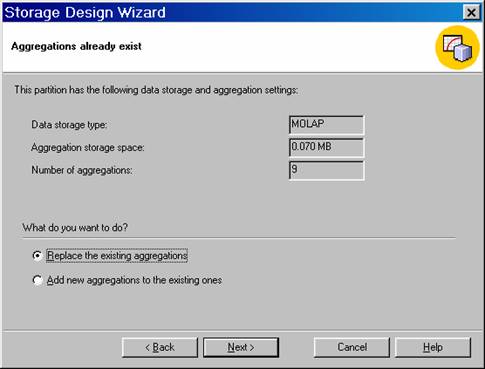
The user can replace the existing aggregations or add new aggregations to the existing ones. But he cannot change the storage mode in this screen. The next screen permits him to change the storage mode.
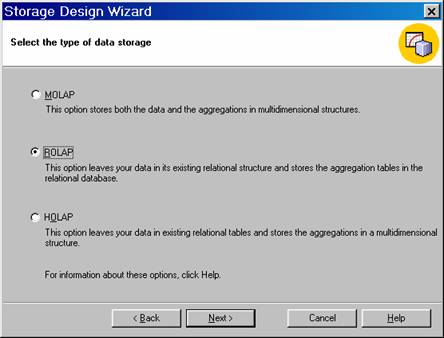
Significantly, a change in the storage mode will make no difference to the client application which only sees the cubes and not the storage types. The user should keep in mind that ROLAP is recommended when resources are not available for MOLAP or the users depend on some functionality of the underlying relational system. If query time is the deciding factor, MOLAP should be used. HOLAP should be used when both processing speed and disk space constraints are in operation.
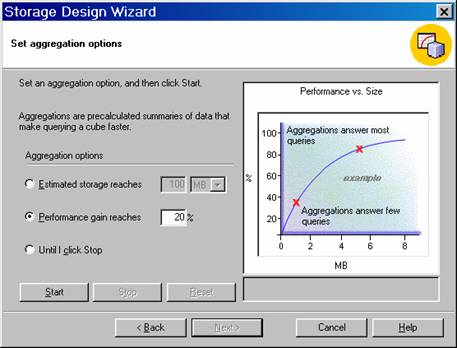
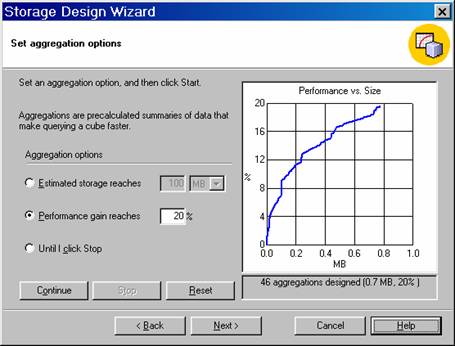
On clicking Next the user is taken to the Set Aggregations screen. Aggregation design is perhaps the single most important factor that impacts on the times required for processing and querying the cube. Creating the right set of aggregations is a very complex problem and Analysis Services estimates usages statistically. The Storage Design Wizard tries various combinations of aggregations and selects a few specific aggregations as the best choices for the cube. The user has no control over which of the few will be selected. In the screen shot below 46 aggregations have been selected.
The options available in this screen are:
Estimated storage reaches is used to enter the amount of hard disk storage to allocate for storing the aggregation tables. The user can enter a maximum storage size in either megabytes (MB) or gigabytes (GB).
Until I click Stop is used to manually control the balance. Watch the Performance vs. Size graph to determine when the increase in performance levels off, even though storage continues to build.
The Wizard asks the user to specify the percentage amount of performance gain for your queries. This amount represents the percentage improvement between the maximum and minimum query times, as represented by the following formula. PercentGain = 100 * (QTimeMAX – QTimeTARGET) / (QTimeMAX – QTimeMIN). For example, if a query that is not optimized takes twenty-two seconds (QTimeMAX) to execute, and the best possible query performance with maximum aggregations is two seconds (QTimeMIN), specify a 75% desired performance gain to achieve a query time of seven seconds (QTimeTARGET).
Click the Performance Gain Reaches and type 20% as the target performance percentage. Then click Start. When the Next button becomes enabled, Click Next.
{mospagebreak}
The Reset button can be clicked at any time to clear the aggregations.
On the Finish screen of the Storage Design Wizard, Click the Process Now option and Click Finish.
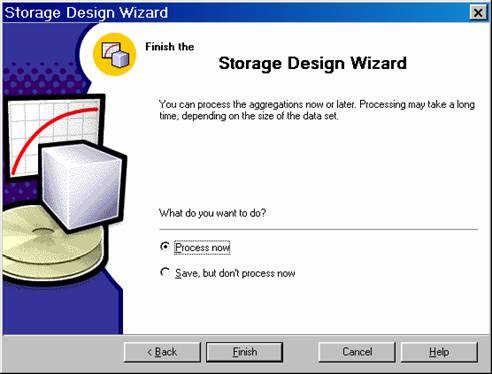
What ever the option selected, Analysis server stores the definition of the aggregations in the OLAP repository. The Storage Design Wizard designs aggregations but does not create them. The aggregations get created only when the cube is processed.
Close the Process Log window after the cube has been processed.
Note that for very large databases with many dimensions, levels, members designing aggregations can take a very long time. A very sophisticated algorithm is executed by Analysis Server behind the scenes. Navigation of hierarchies of a dimension, and combinations of aggregations are examined with the view to optimize performance with minimum storage space requirements. Different partitions of cubes can have different aggregations and will have to be separately designed.
[catlist id=181].